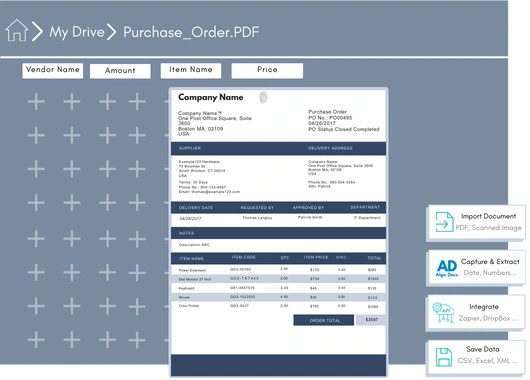
How to Extract PDF Data with ChatGPT?
We are all familiar with PDFs—an essential document format used for sharing textual data. However, extracting data from a PDF can be a challenging task due to the way information is stored within the file. There are two primary types of PDFs: native PDFs, which are usually editable, and scanned PDFs, which contain images of documents saved as PDF files. Both types are widely used in professional and personal settings. You may have a 50-page document of important notes or receive a 1,000-page scanned report from your manager. Extracting data from these two types of PDFs requires different approaches. Native PDFs are easier to process, while scanned PDFs need advanced OCR and AI capabilities for accurate and efficient data extraction. That’s why we’ll explore how to use the powerful LLM model, ChatGPT, to extract data from PDFs. Additionally, we’ll discuss how AlgoDocs AI provides a more precise and efficient solution for handling both types of PDFs. Before diving into PDF data extraction with ChatGPT, it’s essential to understand the basics. PDFs can vary greatly—some contain plain text that is easy to extract, while others have scanned images, complex tables, or charts that require extra processing. Knowing the type of PDF you’re working with is the first step. ChatGPT, developed by OpenAI, is excellent at processing text but does not directly read PDFs. You need to convert the PDF content into a format it can handle, such as plain text. What You’ll Need: Understanding these essentials will make the PDF data extraction process smoother and more efficient. Now, let’s break down the process into five simple steps that anyone can follow, even without technical expertise. Step 1: Preparing Your PDF File Ensure that your PDF is ready for extraction. If it’s a native text-based PDF, it’s good to go. If it’s a scanned document or an image-based file, use AlgoDocs AI or Adobe Acrobat to convert it into an editable format. While ChatGPT can process scanned PDFs, it may struggle with blurry or unstructured data, leading to errors or inaccurate results. Step 2: Feeding Data into ChatGPT Once you have extracted the text, open ChatGPT and paste it into the chat box. However, don’t just drop the text in without guidance. Provide ChatGPT with clear instructions. For example: If you have a simple PDF and need full data extraction, you can use a straightforward command like: This method works well for small-scale extractions but may become difficult when dealing with large datasets. Step 3: Structuring and Extracting Insights ChatGPT will process your request and present the extracted data. If the output is unorganized, refine your prompt: By tweaking your queries, you can refine the results for better readability and usability. Step 4: Troubleshooting Common Issues If ChatGPT misses data or produces inconsistent results, consider: Step 5: Improving Your Extraction Results For more effective results: Use precise prompts to minimize errors (e.g., “Extract all email addresses from this text”). While ChatGPT is powerful, it has limitations: These limitations highlight why ChatGPT is best for quick extractions rather than large-scale automated tasks. For more advanced PDF extractions, AlgoDocs AI offers several advantages over ChatGPT: For instance, if you’re processing invoices, ChatGPT might only extract limited structured data, while AlgoDocs AI allows you to extract invoice numbers, item lists, and totals accurately. Extracting PDF data with ChatGPT is a useful skill for handling small projects efficiently. By converting PDFs to text and providing clear instructions, you can extract valuable insights. However, ChatGPT has its limitations, especially with scanned and complex PDFs. For more precise and large-scale extraction, AlgoDocs AI provides a faster and more reliable alternative. Whether you choose ChatGPT or AlgoDocs, mastering PDF data extraction can save time and enhance productivity.