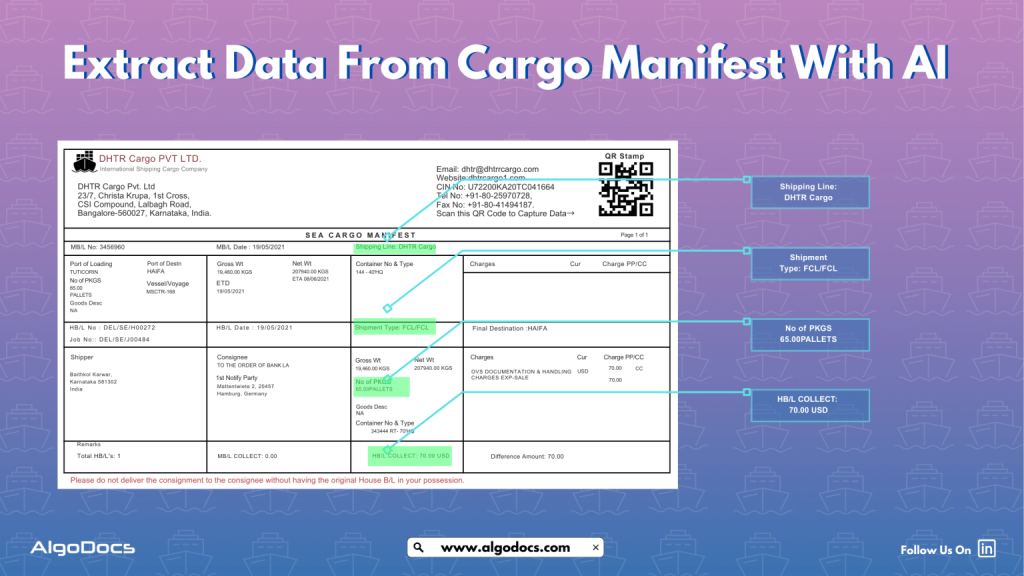
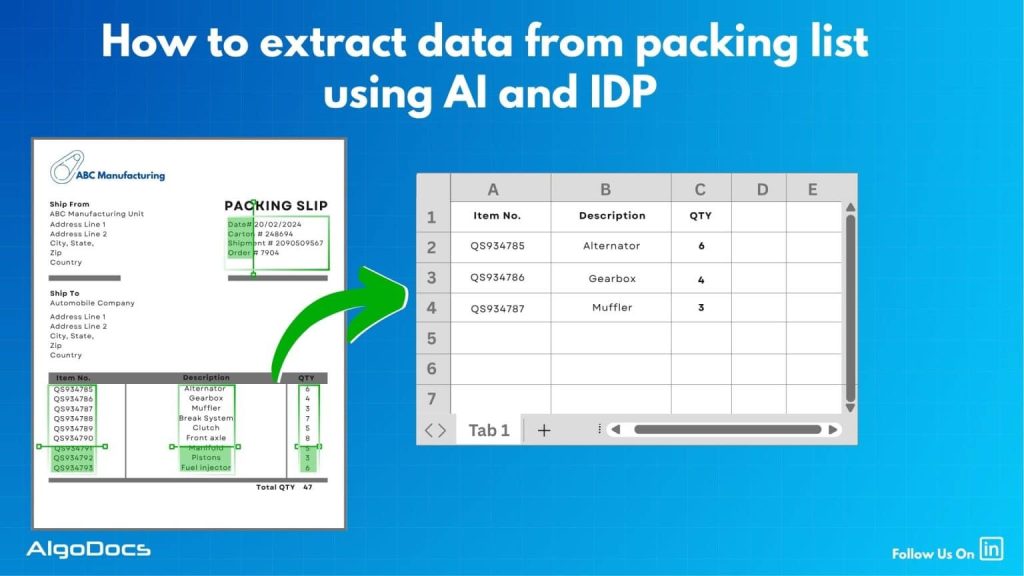
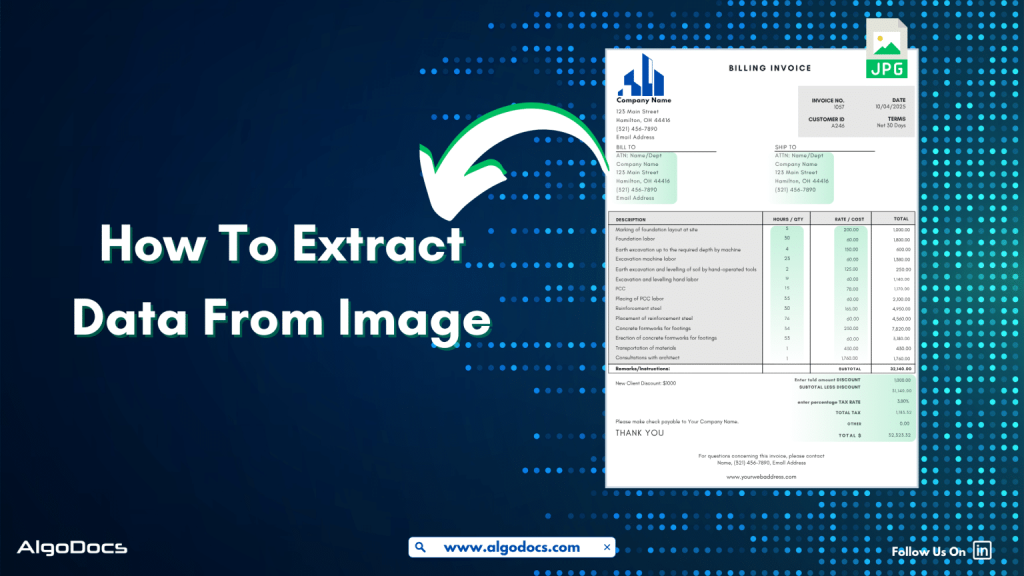
What Is Zonal OCR? An Easy Guide to Understanding Zonal OCR and How It Works.
Processing data from bulk documents can be an annoying and time-consuming task if you have to extract this data manually. But with the help of modern technology such as optical character recognition, you can extract data from these documents easily. There is another part of OCR technology known as zonal OCR, which lets you extract specific data from specific sections of a PDF or scanned image. That is known as zonal OCR. So, what is Zonal OCR, and how does it work? We will discuss more in detail below. Understanding the Basics: OCR VS Zonal OCR? Before we explain what zonal OCR is, we first need to understand what OCR technology is and how it works.OCR stands for Optical Character Recognition. It was developed in the late 70s and started to gain traction in the late 80s. One of the main reasons it gained popularity in the 80s was because it started to be used by banks to extract data from various types of documents, which helped them save time and improve data extraction quality. Later, OCR was adopted in business, marketing, and other industries all around the world.The main function of traditional OCR technology is to convert different types of documents such as scanned paper documents, PDFs, or images into editable and searchable data. An OCR tool “reads” text on an image and turns it into digital letters that are editable on a computer. For example, if you scan a printed invoice and use OCR software, the software can pull out the name, address, and price from that scanned image and turn it into usable text. But classic OCR tools extract all the presented data in a document, and you can’t control what to extract and what not to—that’s where zonal OCR comes into play. What Is Zonal OCR? Now that we know what OCR is, let’s answer the main question—what is zonal OCR?Zonal OCR is a more focused and intelligent version of regular OCR. Instead of scanning an entire document and pulling out all the text, zonal OCR extracts data from specific areas or “zones” of a document. That’s why it is called zonal OCR or is known as template OCR as well. These zones are predefined sections where certain types of information always appear.Think of it like this: if every invoice you receive has the “Invoice Number” in the top right corner, Zonal OCR can be trained to look at just that area and pull the number out automatically. It ignores everything else and goes straight to the point. That makes it incredibly efficient and reliable for high-volume document processing. One of the major highlights of zonal OCR is that it is more accurate compared to traditional OCR. So, How Does Zonal OCR Work? Let’s break down how Zonal OCR works in a step-by-step process: Features of Zonal OCR What makes zonal OCR so powerful is its accuracy. Traditional OCR might pick up irrelevant text or make errors when faced with complex layouts. But zonal OCR knows exactly where to look because we have already defined the zone from where data needs to be picked and extracted. That means fewer errors, faster processing, and smoother workflows. Real-World Example: Zonal OCR For Medical Billing Imagine a hospital that receives thousands of medical bills every month. These documents have patient names, billing codes, diagnosis details, health insurance info, and payment terms.Using zonal OCR, the hospital can define zones on its standard bill layout:• Top left for patient name• Top right for bill number• Centre zone for treatment codes and costs• Bottom section for insurance informationEach incoming bill gets processed automatically. The software reads just those parts and enters the data into the hospital’s billing system. No manual typing. No human errors. Just fast, accurate data extraction. Where Zonal OCR Is Used Zonal OCR is widely used in different industries that handle large volumes of documents with structured layouts. Here are some common use cases:• Healthcare: Extracting patient data, diagnosis reports, medical codes, and insurance details from forms and bills.• Finance: Pulling out transaction info, invoice numbers, and payment dates from bank statements or receipts.• Logistics: Reading shipping labels, barcodes, and delivery addresses.• Legal: Extracting case numbers, parties involved, or dates from legal filings.• Retail: Processing receipts and purchase orders for inventory management. Why Businesses Need Zonal OCR Now that you understand what zonal OCR is, let’s explore why it’s such a vital tool for modern businesses.Saves TimeManual data entry is slow and expensive. Zonal OCR does in seconds what might take a person several minutes or hours.Reduces ErrorsHumans make mistakes, especially when tired or rushed. Zonal OCR provides consistent and accurate results.Scales EasilyWhether you process 10 or 10,000 documents a day, zonal OCR can handle it. It grows with your needs.Easy IntegrationMost zonal OCR systems can plug right into your existing software—like CRMs, ERP tools, or cloud databases.Improves ComplianceAccurate document processing means better audit trails, stronger recordkeeping, and improved compliance with industry regulations. Zonal OCR vs Full-Page OCR You might be wondering, “Why not just use full-page OCR?” Good question!Full-page OCR is great when you want to capture everything from a document, especially if the layout changes often. But it’s not as accurate when you’re looking for specific data.Zonal OCR, on the other hand, works best for structured documents—forms, invoices, claims, or any document where data always appears in the same place.In short:• Full-page OCR = wide net• Zonal OCR = laser focus Intelligent Document Processing (IDP) and Zonal OCR Zonal OCR is often part of a larger automation ecosystem called Intelligent Document Processing (IDP). IDP combines OCR with AI, NLP (Natural Language Processing), machine learning, and workflow automation to fully digitize document handling.In an IDP system:• Zonal OCR extracts the key fields.• NLP understands the context.• Machine learning adapts to new layouts over time.• Automation tools push the data into your systems.This is how modern organizations achieve end-to-end document automation—saving costs, improving accuracy, and speeding up operations. Challenges of Zonal OCR (and How to Overcome Them) While zonal OCR is incredibly