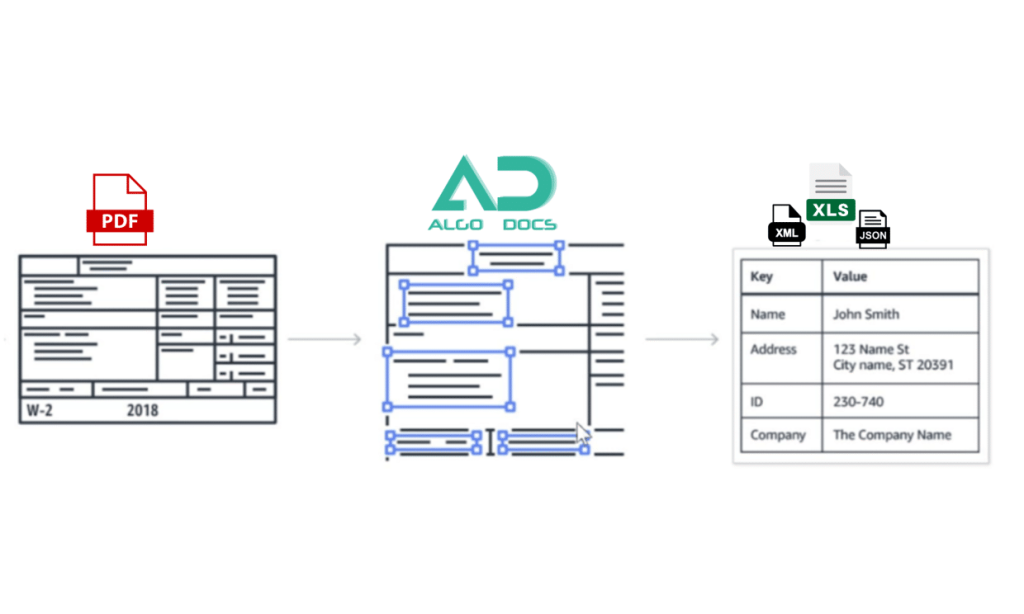
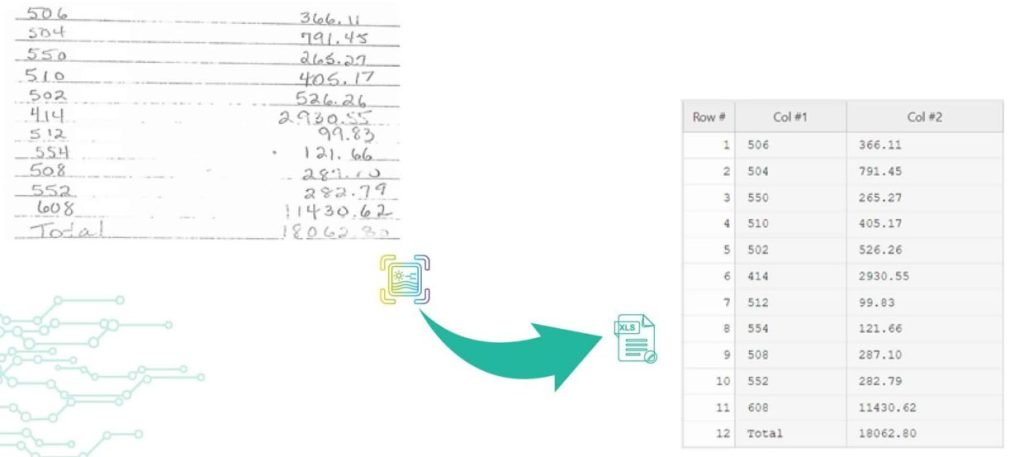
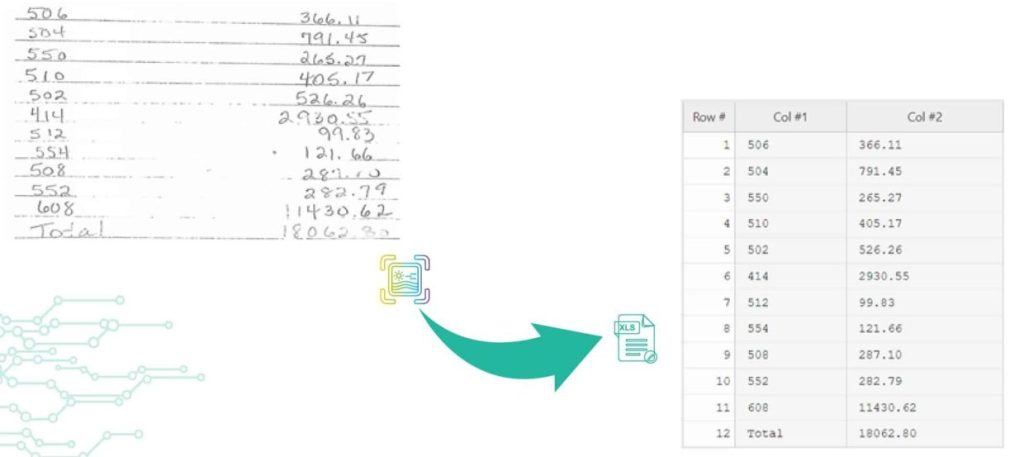
IDP Use Case: Transforming Restoration Practices
Earthquakes, hurricanes, mudslides, electrical fires, and burst pipes are some of the natural incidences that are usually unforeseen. Buildings that are often at the receiving end during catastrophic calamities require immense repair work. Any comprehensive structure will, in this respect, indeed call for disaster recovery management, especially if it is a house or a company. It has scaled tremendously to be vital software in the construction industry, but it is notably critical in the catastrophe repair industry, where most companies are small. Table of Contents: But as structures progress, many organizations like yours struggle to cope with change. Often, the driving force of success is in the technology that forms the basis of these organizations. Let us think of the building and restoration industry and see what we come up with. These companies have to estimate all possible costs for a building construction project, including additional costs such as salary for office employees, wear and tear of equipment, office rent and other overhead expenses, and cost of all the materials used and wages to workers. Enhancing Data Management in Restoration Processes Intelligent Document Processing (IDP) tools can capture information from any format that has not been pre-formatted, including images and handwritten writings. This can be of great importance, especially in restoration processes where data could be in large quantities, in the form of field notes and sketches, among other things. The Importance of Accurate Costs and Expenses Some of the factors one needs to understand well to accurately estimate the cost of the project include the building material costs, the requirements, the procedures, and the codes that are to be followed, as well as the need to understand the market trends in terms of pricing. Such information may be found by analyzing a bid package and working through the contingencies and profit inherent in a bid or a given project. Two Significant Challenges: Documentation obstacles: One of the challenges associated with restoration events is collecting all the relevant and non-concocted paperwork. Some of the effects of this cumbersome procedure include the failure to complete some forms or the delay in completing them. Accounts Receivable Delays are attributed primarily to fourteen struggles stemming from a high turnover rate in accounting: payment cycles take longer. This not only impacts cash flow but also definitely causes a lot of headaches for the business’s dealings with its customers. The Impact of Intelligent Document Processing (IDP) Software on Restoration Businesses: Implementing Intelligent Document Processing (IDP) Several Challenges. Here are some of the key ones: Case Study Use case for restoration: The repair company wishes to provide the customer with an overview of line-item estimates for the job. Cost estimates should not be utilized as a list of negotiable items. Supplemental costs may apply if more damage or repair that has not been found or is hidden below present finishes is required. This also enables the client to correct himself or herself if they chose compositions that are not within the estimate or if they need extra work. This is because, in the course of the project implementation, changes will be made to adjust for the revised estimate and present it to the client. Any changes made to these documents will be recorded in a change order and presented to the customer for revision. System: It is a form of advanced digital document processing with natural language processing, multimedia processes, and feature extraction. Primary actor: Accountant/bookkeeper/Customer Scenario: To meet the customer’s request to extract the estimated line-item information from the final amount, the following processes should be considered: They ask for the extracted data to be formatted differently than the original document’s formatting. They clearly explain what should be ignored and what needs to be extracted. There are a total of 11 headers in the PDF; each row value contains three different pieces of information: one is the labor, the second is the material, and the third is the equipment information. They need to extract the labor and material information. For example, the following are the instructions for the needed to be extracted data and how it should look like output: Tabular output with headers and the order they should be in JSON form: ·”ITEM#”, mapped from the label in Yellow (as in the picture above) ·”ROOM”, mapped from the label in dark green (as in the picture above) ·”UNIT”, mapped from the label in Red (as in the picture above) ·”QTY”, mapped from the label in light blue (as in the picture above) ·”UNIT PRICE”, mapped from the label in light green (as in the picture above) ·”TOTAL” mapped from the label in pink/magenta (as in the picture above) However, we still need to extract and differentiate data for Labor and Material information. While mapping the extracted data to the new headers, as requested by the customer. As complicated as it looks and sounds, Algodocs can do exactly this request easily. How to Use Algodocs to Extract We only need a sample file uploaded to Algodocs to create the extractor. There are many ways to upload a sample document. The user can automate importing files to Algodocs uploading from their device, business email, Gmail, or other cloud storage. Once the documents are uploaded, the system will extract data from your documents using Algodocs’ advanced AI engine without relying on templates or even labeling and training your files. The results are the actual contents extracted from the sample document according to the rules you specify. We have Rule-based extraction and artificial intelligence mining, which can be integrated to synthesize both extraction methods. This can help you further improve your extracted data by putting it into the correct form and structure. The system makes it easy to control extracted data from your documents and handle business exceptions. It allows you to export the extracted data directly to an Excel Spreadsheet or, with the integration of Zapier, automate exporting extracted data directly to your email, Google Sheets, or other cloud storage. Example of Output in Excel Key Takeaways This should explain how Algodocs has boosted the restoration business and its experience with the solution to prove that technology can transform any business. Let your team be an example of how adopting effective and progressive concepts can