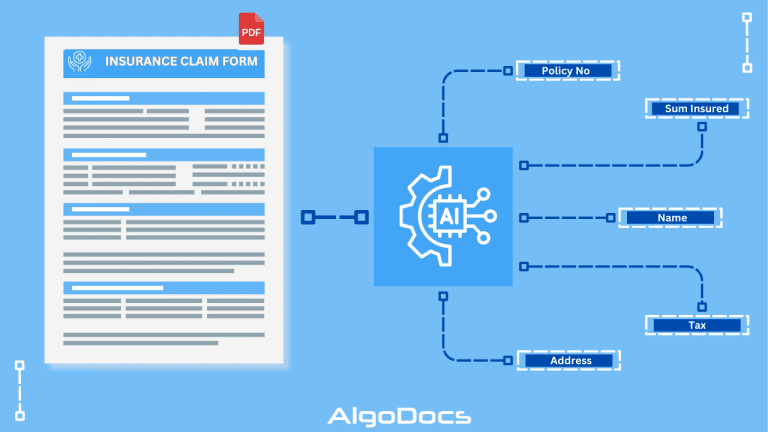
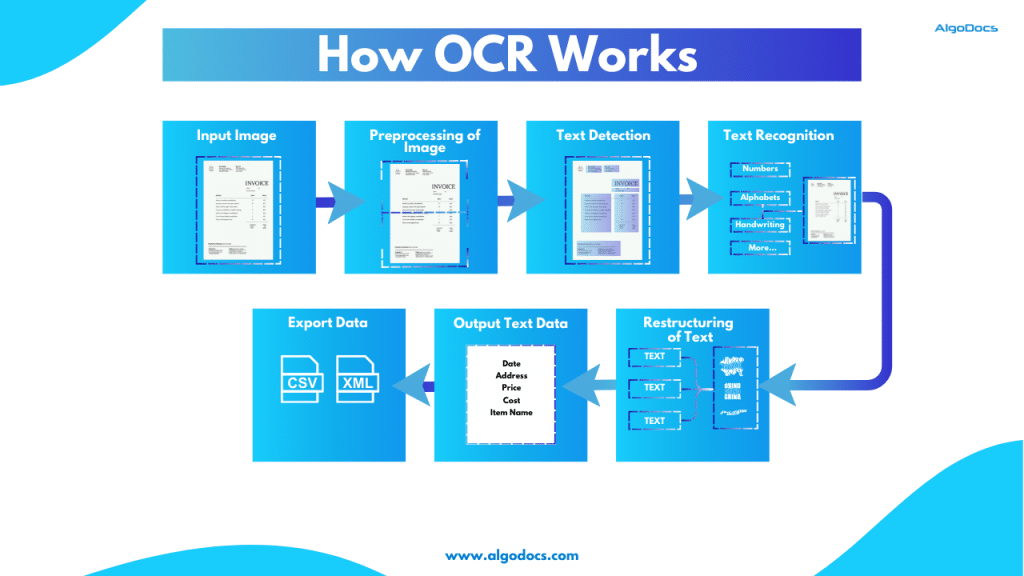
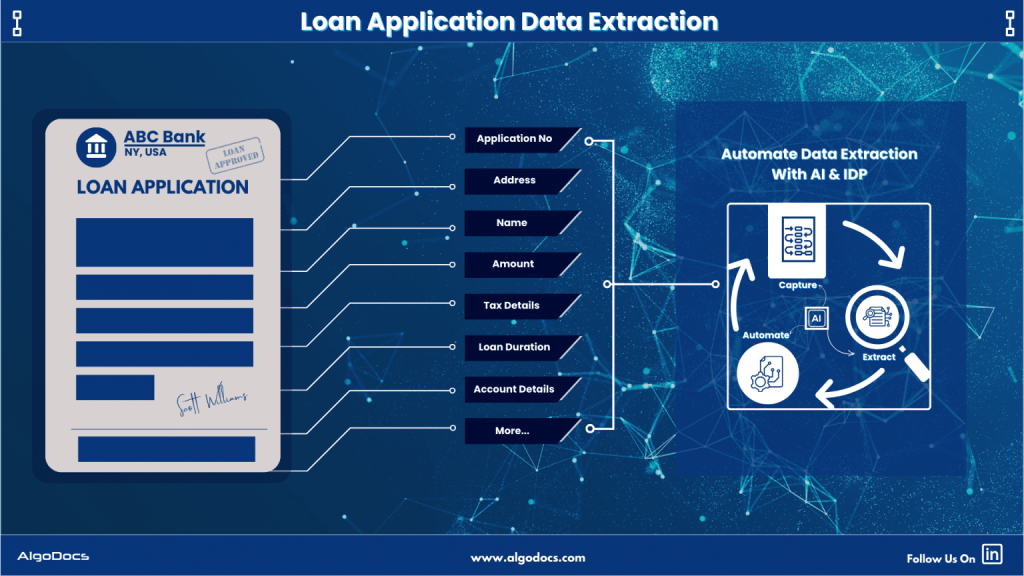
OCR vs IDP: Which one is better? How to choose the right technology to elevate your business.
The debate OCR VS IDP—often sparks conflicting opinions, as the choice depends on the specific needs and nature of the technology required. Both technologies serve the purpose of extracting data from various types of documents for business and personal use. In today’s data-driven world, businesses face the challenge of managing vast amounts of information stored in physical and digital documents. Efficient and accurate data extraction has become essential for streamlining operations, enhancing decision-making, and maintaining a competitive edge. Two technologies are leading this data extraction revolution: Optical Character Recognition (OCR) and Intelligent Document Processing (IDP). Although often used interchangeably, these technologies offer distinct capabilities and serve different purposes. This comprehensive guide will explore the key differences between OCR and IDP, their ideal use cases, and how to determine the right solution for your business needs. What is OCR? Optical Character Recognition (OCR) is a technology that converts images into machine-readable text data. These documents can be handwritten notes, typed, or printed in the form of PDFs, word documents, or image files. It works by analyzing the visual patterns of characters and comparing them to stored character sets. Once recognized, the text can be edited, searched, and stored electronically. Think of it as a digital eye that scans a document and translates visual characters into a digital language that computers can understand. OCR technology helps save time, reduce human errors during data extraction, and lower operational costs. Although OCR technology has been around for a long time, it has gained significant traction in recent years. Businesses increasingly rely on OCR-based tools for various data extraction and document processing tasks, driven by the growing need to manage and extract large volumes of data efficiently. What is IDP? Intelligent Document Processing (IDP) is a revolutionary advancement that leverages Artificial Intelligence (AI) and Machine Learning (ML) to enhance document processing workflows. Unlike OCR, which is limited to reading and extracting text from documents, IDP takes things a step further by analyzing, filtering, sorting, and automating data extraction from a variety of sources, including emails and other digital platforms. IDP builds on OCR by integrating AI and ML to automate the entire document processing lifecycle. It doesn’t just recognize characters; it understands the context and meaning of the extracted information. IDP systems can classify documents, extract specific data fields (such as names, dates, or invoice numbers), validate the data, and seamlessly integrate with other business systems. Think of it as a digital assistant that not only reads documents but also comprehends their purpose and extracts the most relevant information, making your workflows smarter and more efficient. Key Differences Between OCR and IDP The fundamental difference lies in their level of intelligence and automation. OCR focuses solely on character recognition, while IDP handles the entire document processing lifecycle. Here’s a breakdown: Feature OCR IDP Core Function Converts images of text to machine-readable text Automates the entire document processing workflow, including classification, data extraction, validation, and integration. Intelligence Basic character recognition Advanced AI and ML algorithms for context understanding, data validation, and learning from new document types. Automation Limited to text extraction High level of automation, capable of handling complex document layouts and variations. Data Extraction Extracts all text present in the image Extracts specific data points based on predefined rules or machine learning models. Document Types Simple, structured documents with consistent layouts Complex, semi-structured, and unstructured documents with varying layouts and formats. Error Handling Prone to errors with low-quality images or complex layouts More robust error handling through data validation and human-in-the-loop verification. Scalability Limited scalability for complex document processing Highly scalable for large volumes of diverse documents. When is OCR a Good Choice? OCR is a suitable solution when dealing with: When is IDP a Good Choice? IDP is the preferred choice for: Types of Documents Can Be Processed by OCR OCR excels at processing: Types of Documents Can Be Processed By IDP IDP can handle a wider range of documents, including: Industries Benefiting from OCR Industries that can benefit from OCR include: Industries Benefiting from IDP IDP offers significant advantages to industries dealing with large volumes of complex documents: How To Choosing Between OCR and IDP The choice between OCR and IDP depends on your specific business needs and document processing requirements. OCR is a suitable option for small businesses that handle a limited number of documents and need basic data extraction. However, for companies managing a large volume of documents across various categories and aiming to automate the entire process with third-party platforms, IDP is the better choice. Below are a few key factors to help you decide which option is best for your business. Algodocs IDP Platform: A Powerful Solution Algodocs is a robust intelligent document processing platform that offers a comprehensive suite of features for automating document processing. It leverages advanced AI and ML algorithms to accurately extract data from various document types, including invoices, contracts, and forms. Key features of Algodocs include: Signup for Algodocs free-forever plan today and access all the advanced features for free. Conclusion OCR and IDP are powerful technologies that transform how businesses handle document data. While OCR serves as a valuable tool for basic text extraction from simple documents, IDP provides a more comprehensive and intelligent solution for automating complex document processing workflows. By understanding the key differences between these technologies and carefully evaluating your business needs, you can choose the right solution to unlock the valuable information trapped within your documents and drive greater efficiency and productivity. For businesses facing complex document challenges and seeking a robust, scalable solution, a platform like Algodocs offers a compelling path towards automated document processing and data-driven insights.